堆排序算法思想
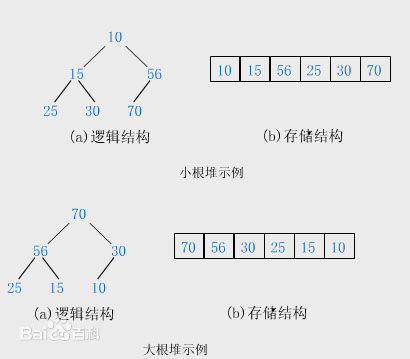
n个关键字序列Kl,K2,…,Kn称为(Heap),当且仅当该序列满足如下性质(简称为堆性质):
(1)ki<=k(2i)且ki<=k(2i+1)(1≤i≤ n/2),当然,这是小根堆,大根堆则换成>=号。k(i)相当于二叉树的非叶子结点, K(2i)则是左子节点,k(2i+1)是右子节点,若将此序列所存储的向量a[1..n]看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:树中任一非叶子结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字。
大根堆和小根堆:根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最小者的堆称为小根堆,又称最小堆。根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最大者,称为大根堆,又称最大堆。注意:①堆中任一子树亦是堆。②以上讨论的堆实际上是二叉堆(Binary Heap)。
用大根堆排序的基本思想
1.先将初始文件a[1..n]建成一个大根堆,此堆为初始的无序区。
2.再将关键字最大的记录a[1](即堆顶)和无序区的最后一个记录a[n]交换,由此得到新的无序区a[1..n-1]和有序区a[n],且满足a[1..n-1].keys≤a[n].key。
3.由于交换后新的根a[1]可能违反堆性质,故应将当前无序区a[1..n-1]调整为堆。然后再次将a[1..n-1]中关键字最大的记录a[1]和该区间的最后一个记录a[n-1]交换,由此得到新的无序区a[1..n-2]和有序区a[n-1..n],且仍满足关系a[1..n-2].keys≤a[n-1..n].keys,同样要将a[1..n-2]调整为堆。
……
直到无序区只有一个元素为止。
大根堆排序算法的基本操作:
1.建堆,建堆是不断调整堆的过程,从len/2处开始调整,一直到第一个节点,此处len是堆中元素的个数。建堆的过程是线性的过程,从len/2到0处一直调用调整堆的过程,相当于o(h1)+o(h2)…+o(hlen/2) 其中h表示节点的深度,len/2表示节点的个数,这是一个求和的过程,结果是线性的O(n)。
2.调整堆:调整堆在构建堆的过程中会用到,而且在堆排序过程中也会用到。利用的思想是比较节点i和它的孩子节点left(i),right(i),选出三者最大(或者最小)者,如果最大(小)值不是节点i而是它的一个孩子节点,那边交换节点i和该节点,然后再调用调整堆过程,这是一个递归的过程。调整堆的过程时间复杂度与堆的深度有关系,是logn的操作,因为是沿着深度方向进行调整的。
3.堆排序:堆排序是利用上面的两个过程来进行的。首先是根据元素构建堆。然后将堆的根节点取出(一般是与最后一个节点进行交换),将前面len-1个节点继续进行堆调整的过程,然后再将根节点取出,这样一直到所有节点都取出。堆排序过程的时间复杂度是O(nlogn)。因为建堆的时间复杂度是O(n)(调用一次);调整堆的时间复杂度是logn,调用了n-1次,所以堆排序的时间复杂度是O(nlogn)。
堆排序时间复杂度O(n*logn)。空间复杂度O(1)。堆排序不是稳定排序算法。