scrapy框架介绍
框架(Framework)是整个或部分系统的可重用设计,表现为一组抽象构件及构件实例间交互的方法;另一种定义认为,框架是可被应用开发者定制的应用骨架。简单讲框架是指对某一技术进行抽象,提取出共同的特征,将其进行固化,使用框架可以避免重复造轮子,提高开发效率。在第二章中我们介绍了爬虫的爬取流程,一般为请求网页,提取数据,存储数据。scrapy就是根据爬虫爬取数据流程设计的一种python爬虫框架。
scrapy框架原理如下图所示。
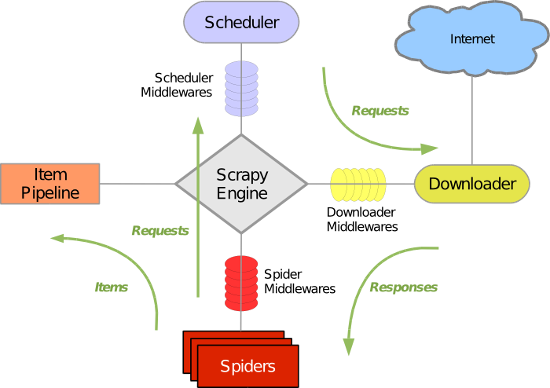
引擎(Scrapy Engine):用来处理整个系统的数据流处理,触发事务。
调度器(Scheduler):受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
下载器(Downloader)下载网页内容,并将网页内容返回给蜘蛛。
蜘蛛(Spiders):主要干活的,用它来制订特定域名或网页的解析规则。编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
管道(Item Pipeline):理有蜘蛛从网页中抽取的项目,他的主要任务是清洗、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件(Downloader Middlewares):scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
蜘蛛中间件(Spider Middlewares):介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件(Scheduler Middlewares):介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
不要被上述的名词所吓倒,在实际应用中我们一般只使用三个模块,一是Spiders,这个模块负责定义抓取地址和抓取规则并进行页面抓取;二是items,负责定义抓取的数据格式;三是PipeLine,负责将抓取到的数据进行处理。