爬虫相关知识
爬虫的主要工作是爬取网页上的各类信息,目标网站出于保护信息,降低负载等原因一般会有反爬措施,此外不同网站有不同的页面结构和页面生成策略,所以在爬取网站信息时有很多通用的小知识需要了解和掌握。
1.设置cookie
有些网站需要登录后才能进行下一步操作,此时发送的请求一般需要携带cookies,发送带有cookies的请求流程一般为首先获取cookies,然后使用cookies。requests获得cookies的语句如下
mycookies=requests.get(url).headers.get('cookie')
2.保持会话
在需要登录的网站中,除了发送带有cookies的请求外还需要保持会话,使用requests.Session()可以保持会话,这样登录以后就可以继续操作其他页面。3.使用代理
当频繁爬取一个目标网站时,目标网站可能会随机弹出验证码或者将爬虫的源IP封掉,禁止访问。此时,使用代理便可解决以上两个问题。使用代理的一般代码如下proxies = {"http":"http://XX.XX.XX.XX:XXXX"}
response = requests.get(url=url, proxies=proxies)
4.验证码识别
对于需要输入验证码的网站,有两种解决办法:一种是手工输入提交,另一种算法识别。目前对于简单的验证码可以使用google的pytesser库进行识别,但复杂验证码识别率很低,所以对于需要填写验证码的页面还是手工查看输入提交效率更高。5.伪装浏览器
将爬虫请求伪装成为普通浏览器的请求可以有效的防止被目标网站封掉,伪装请求主要是设置请求request的头部。头部信息通过chrome可查看,如下图:
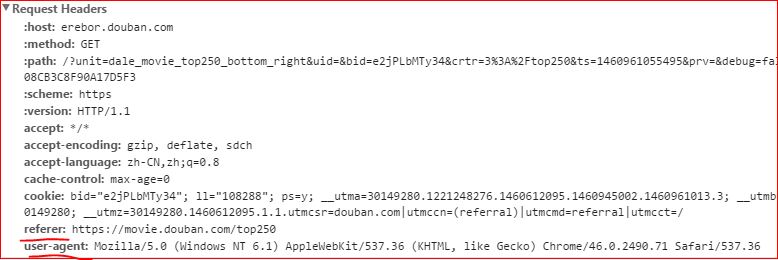 设置头部的语句如下:
设置头部的语句如下:
headers = {'User-Agent':'XXXXX', 'Referer':'XXXXX'}
response = requests.get(url=url, headers=headers)
为了减轻目标网页的访问压力,进而防止被目标网站封掉,一般需要限制爬取频率,限制爬取频率可以使用time.sleep(x)来控制爬虫爬取速度,x的取值一般为2或3即可。