HTML基础
本节主要讲述HTML的基本概念。爬取网页首先要对网页有基本了解,入门网页知识可以访问 w3c school 学习
1. 页面组成
一个页面通常由css,js和html元素构成,其中css定义了页面的样式,js负责完成动态页面渲染,html元素构成静态页面。 常见的html元素有文本元素text,超链接(一般形式a href='#)',图片(一般形式img src='img.png');css在页面中一般通过 div class='demo'的形式来引用;js以javascript标签形式引用。
常用的查看页面元素的工具是Chrome浏览器的‘审查元素’功能,一个典型的页面元素如下:
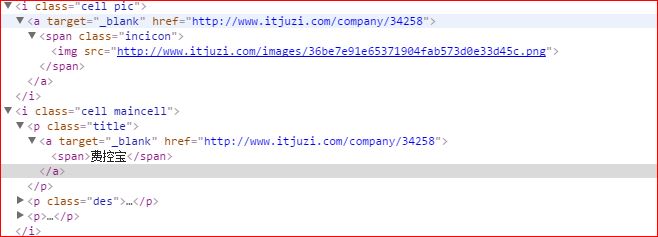
可以看出页面元素都是通过各种标签来组织的。
2. 静态页面和动态页面
网络上最初的web页面都是静态的html页面,页面元素比较简单都是一些文本,图片等信息的展示,但随着js和ajax等技术的发展,web页面逐渐呈现动态化。动态页面可以提供更好的用户体验但是增加了爬虫爬取的困难,对于动态页面,右键‘查看网页源代码’和Chrome下右键‘审查元素’看到的页面结构是不同的。‘审查元素’可以得到动态加载后的页面,在爬虫爬取时需要注意静态和动态页面的区别处理
3. get和post请求
简单来讲,一般访问网页是get请求,当需要发送数据给服务器时使用的是post请求。在爬虫中获取网页信息使用get请求,发送数据给服务器时(如登陆提交)使用post请求。