
解析
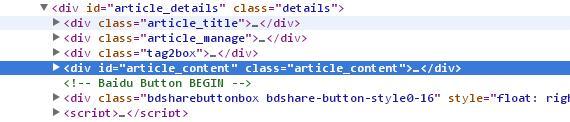
在前一节中已经建立了_pytest 的项目, 在 _onstart 函数后面还有 _indexpage 与_detailpage两个函数,其中_indexpage函数通过回调_detailpage函数来对数据进行解析。比如我们前一节中抓取的页面的html结构如下图,其中深蓝色的部分就是我们想要的内容,由于pyspider支持CSS选择器来获取抓取页面元素的值,如下代码取到id为article-content的值,而在_indexpage函数中的CSS表达式.search-list-con dl dt a[href^="http"] 的作用是进一步去抓取该页中满足条件的链接。
def index_page(self, response):
for each in response.doc('.search-list-con dl dt a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
"content":response.doc('#article-content').text(),
}
这样我们的数据解析部分就完成了。